Chimera
Compositional Image Generation using Part-Based Concepting
1 Arizona State University
2 Georgia Institute of Technology
3 Google Deepmind
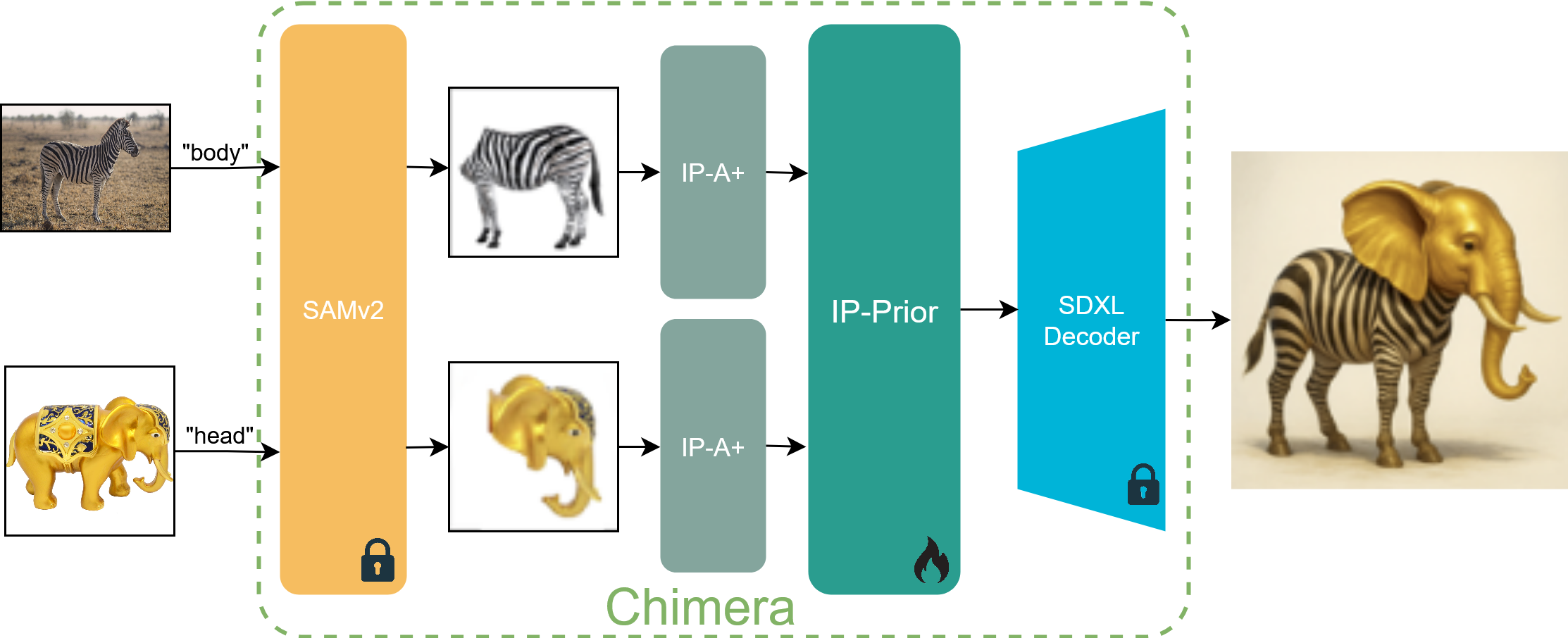
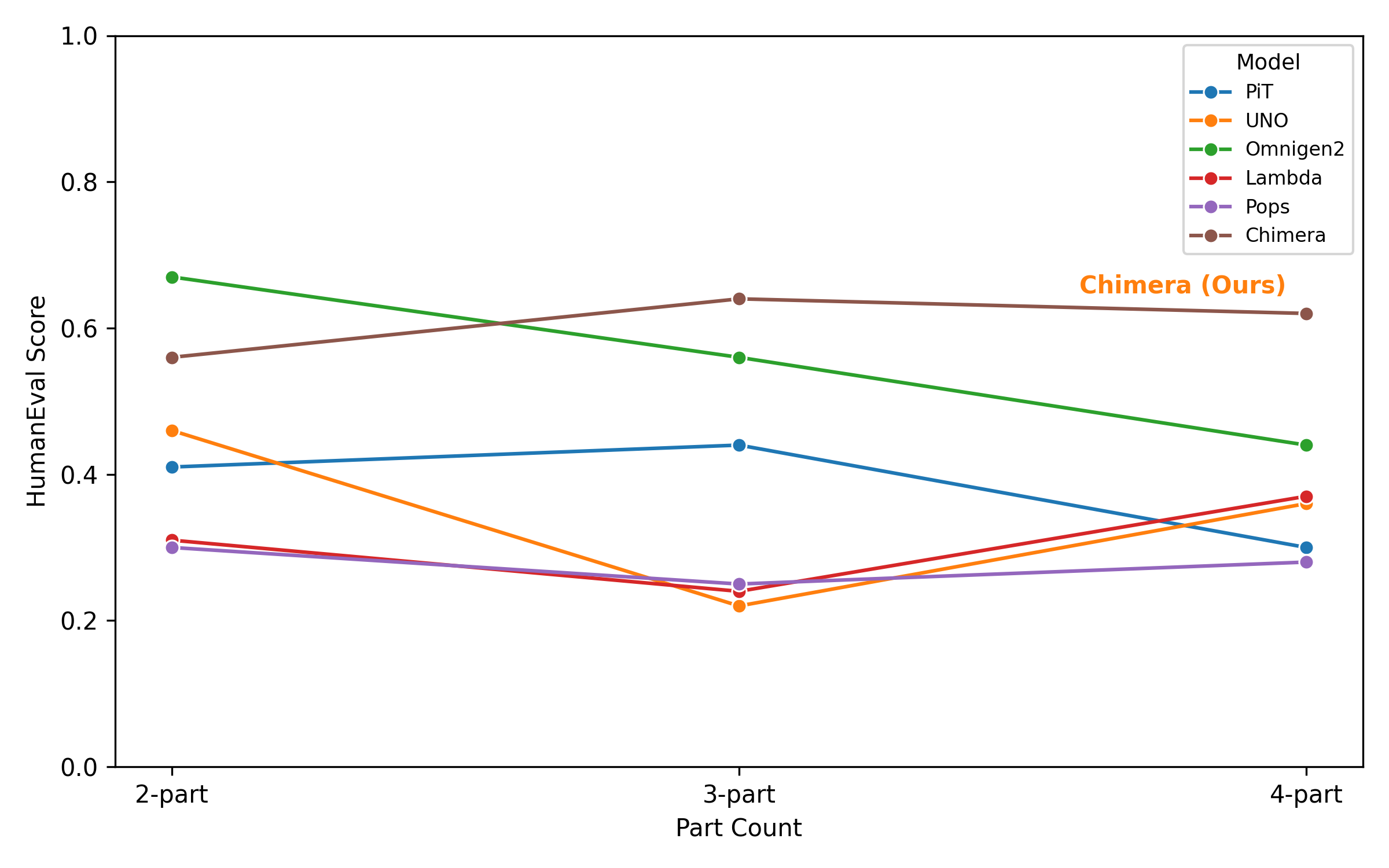
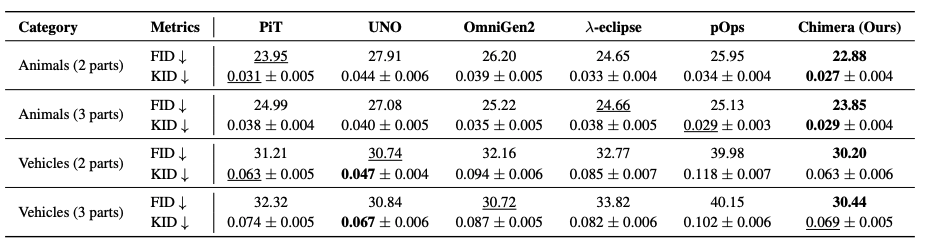
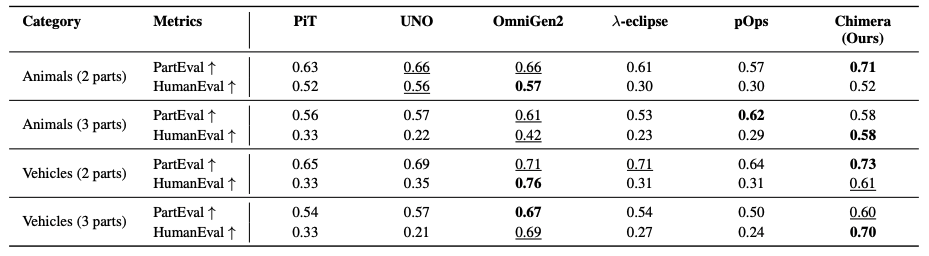
Personalized image generative models are highly proficient at synthesizing images from text or a single image, yet they lack explicit control for composing objects from specific parts of multiple source images without user specified masks or annotations. To address this, we introduce Chimera, a personalized image generation model that generates novel objects by combining specified parts from different source images according to textual instructions. To train our model, we first construct a dataset from a taxonomy built on 464 unique (part, subject) pairs, which we term semantic atoms. From this, we generate 37k prompts and synthesize the corresponding images with a high-fidelity text-to-image model. We train a custom diffusion prior model with part-conditional guidance, which steers the image-conditioning features to enforce both semantic identity and spatial layout. We also introduce an objective metric PartEval to assess the fidelity and compositional accuracy of generation pipelines. Human evaluations and our proposed metric show that Chimera outperforms other baselines by 14% in part alignment and compositional accuracy and 21% in visual quality

@article{singh2025chimera,
title={Chimera: Compositional Image Generation using Part-Based Concepting},
author={Singh, Shivam and Chen, Yiming and Chatterjee, Agneet and Raj, Amit and Hays, James and Yang, Yezhou and Baral, Chitta},
journal={arXiv preprint arXiv:TBD},
year={2025}
}